OpenPose: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields
Glia Comuputing 研究員の芦原です。
今回より,人物認識系の論文の内容を解説していきます.
第1弾は,CMUがGitを公開したことで多くの方に試されているOpenPoseについて解説していきたいと思います.今回の論文は,こちらのリンクから参照できます.CVPR2017で発表されたこの論文がベースですが,OpenPoseが公開された際に,CVPRでの発表時から工夫した箇所等もあったようです.本記事では,それらについても触れていきます.
断りのない限り,本記事で使用する画像や数式は,こちらの論文から引用しています.
目次
紹介する論文の概要
紹介する論文では,画像中や映像中に映る人物について,ただ人がいるということが出力されるだけでなく(人物をBoxで囲うような出力だけではなく),より詳細な情報の認識を目指す領域(Human Pose Estimation)についてアプローチしています.そして,Body,Foot,Hand,Facialのそれぞれの領域についての姿勢の状態を出力するようなシステムであるOpenPoseをリリースしたことを報告しています.
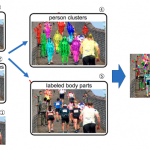
ここで,論文中で扱っているHuman Pose Estimationというタスクについてですが,MPⅡ Human Pose Dataset や COCO,最近ではPosetrack などがデータセットとして使われていることが多いですが,人物を認識する問題だけでなく,その人物の姿勢を推定する問題とも言うことができます(画像1.).この姿勢の推定という問題設定についてはいくつかのアプローチがあり,それについては次章で記述します.

取っているかを検出することがこのタスクの目的となる
Human Pose Estimationにおけるアプローチの紹介
この章では,Human Pose Estimationと呼ばれるタスクがどのようなアプローチで解かれていたかを簡単に紹介していきます.
トップダウン型
画像の中に映っている人の姿勢を推定したいとき,私も含め多くの人が考える方法が,まず画像の中から人らしきものを探索し,特定後にその人の姿勢を推定しようと考えると思います.言い換えれば,「画像中の人の探索→姿勢の推定」といった工程のアルゴリズムを考えるとも言えます.このようなアプローチはトップダウン型と考えられていて,He らのMask R-CNN[1]や,Iqbalらの[2]はそれらの考え方を実現した素晴らしいアルゴリズムです.

※画像はarxiv.org/abs/1608.08526より使用
しかしながら,これらのトップダウン型と呼ばれるアルゴリズムは,人物のカウントと,姿勢の推定を別の工程として行う手法が多かったため,画像中に人が多くいる場合に対しては,数十秒〜数千秒に至るような計算時間が画像1枚に対してかかるといった問題を抱えていました.というのも,これらの方法は画像中にいる人物を一人に絞って,姿勢を推定するような問題(Single Person Pose Estimation)について扱われていたWeiらの[3]のような手法を,Multi Personに拡張するような形式で発展したものが多かったためです.
ボトムアップ型
トップダウン型について述べると,当然それらのアプローチの対極的な考え方としてボトムアップが考えられると思います.ボトムアップ型の考え方は,先に姿勢の推定の鍵となるキーポイントを抽出して,その後にキーポイントを人物ごとにマッチングさせるという考え方です.言い換えれば,「候補点となるキーポイントの抽出→キーポイントどうしのマッチング」といった工程とも言えます.ボトムアップ型のアプローチも数多くの手法が考えられており,PishchulinらのDeepcut[4]もまた,このアプローチを実装した素晴らしいものでした.

※画像はarxiv.org/abs/1511.06645より使用
しかしながら,ボトムアップ型もまた計算時間が課題の一つでした.原因としては,キーポイントの抽出後に,各人ごとにそのキーポイントをマッチングさせる工程で,多くの組み合わせの中から適切なマッチングを抽出する工程に時間がかかってしまうというものでした.また,マッチングの精度自体を高くすることも難しい課題でした.このキーポイントとこのキーポイントが,同一人物のキーポイントである,ということを画像のコンテキストから推定することは難しく,人の重なりや,人っぽい物体の誤検出など,今でも解決したい課題は残されています.InsafutdinovらはDeeperCut[5]という,Deepcutの構造を変更して計算をより効率的に行う方法を考案しましたが,それでも一枚の画像に対して数秒から,画像によっては数百秒かかってしまう結果もあったようです.それらの課題に対しては,DeeprCutなどの論文が出た後,アルゴリズムに改良が施され,CVPR2017では,今回のターゲットとなる論文を著したCaoらの[6]や,InsafutdinovらのArtTrack[7]は画像1枚に対する速度はほぼ同じとなり,特定の条件の下では0.005秒での処理が可能となりました.今回は[6]及びOpenPoseについて解説しますが,ArtTrackについては次回紹介する予定です.
提案手法の解説
前章で述べたように,ボトムアップ型の考え方では,キーポイントのマッチングに時間がかかること,マッチングそのものの精度が課題でした.この章では,OpenPoseがボトムアップ型の諸問題をどのように解決しようとしたのかについて,OpenPoseの手順と手法について解説していきます.
OpenPoseの全体図
最初にOpenPoseの原型とも言える[6]でどのように画像が処理されていくかという図を見ると,以下のような形になります.

※画像はhttps://arxiv.org/abs/1812.08008より一部引用
画像4.の①〜⑤までの処理について概要を記述すると,
① カラー画像の入力情報として扱います
② 入力情報を特徴量にあらかじめ変換します.特徴量に変換する処理は,
入力画像をVGG-19[8]に入力し,中間層を特徴量として使います
③ 人の部位そのもの(キーポイント)について検出を行うConfidence Mapを作成します
④ 人のキーポイントとキーポイントのつながりをPart Affinity Fields (PAF)を使って獲得します
⑤ ③で得たキーポイントと,④で得たつながりを表現する場をマッチングさせます
という流れになります.[6]では,先述したマッチングという課題に対して,キーポイントの検出とキーポイントのつながりを別々に計算し,マッチングさせる仕組みを使っています.次に,OpenPoseの処理を見ていきますと,以下の形になります.

※画像はhttps://arxiv.org/abs/1812.08008より一部引用
画像5.の①〜⑤までの処理について概要を記述すると,①,②,④及び⑤は[6]と同様な処理を行います.③では,これまででは②で得た特徴量のみを入力としていましたが,④の出力であるキーポイントのつながりに関わる情報を合わせて入力する形式にしています.④が③を補助することによって,より精度の高いキーポイントの抽出ができるようになり,(ほぼ)一本道な構造に変えることによって,[6]よりもより早く計算することを期待する構造になっています.ここでのポイントは,
1. あらかじめ入力画像を特徴量に変換しておく
2. キーポイントの抽出と,キーポイントどうしのつながりは別々に獲得しておく
といった点になります.また,OpenPoseにおける③と④の処理部分については,以下のようになっています.

ベージュ色で囲まれた部分が③に相当する
論文中ではStageと呼ばれる単位で青色やベージュ色で囲まれた部分を重ねていきます.そして青色部分を4Stage,ベージュ色部分を2Stage重ねた形で実装しています.画像の特徴量をF,青色部分で計算される過程をL,ベージュ色部分で計算される過程をS,画像中の座標をpとすると,各Stageが学習する過程を式で書くことができます.

青色部分のPAFを出力する部分は上記の式に従って,学習をしていきます.出力が式の中の①となっており,②が教師データで,③がバイナリマスクとなっています.バイナリマスクの役割は,True-Positiveの際のペナルティを緩和するために挿入しています.①,②部分をどのように決めるかについては,3.3で記述します.

ベージュ色のConfidence Mapを出力する部分にいても,PAFを出力するLの過程とほとんど同じように記述されます.①,②の詳しい部分については,3.2で記述します.
ここまでをまとめると,OpenPoseでは,入力情報から特徴量を抽出し,そこからキーポイントそのものを取り出す過程,キーポイントどうしのつながりを検出する過程に分けて考えていることがわかります.ここからは,それぞれの過程を担当するニューラルネットがどのように学習するかについて,もう少し深く記述していきます.ここから先は数式が多くなります.
Part Affinity Fieldsを作成するモデル
PAFを出力する部分は画像5.の青色部分のStage,つまり前章でのLにあたります.Lで行われる処理は,以下のように記述されます.

PAFを計算するStageでは,特徴量及び,直前のStageからの入力をもらいながら,PAFを計算する形を取っています.式中のΦはニューラルネットのパラメータを示していて,画像6.に従えば,Φの正体は畳み込み層を重ねたものであることがわかります.実際にはResidual Blockという手法を使っていますが,ここではΦの中身自体が大事な議論ではないので,その説明は省略します.Lが決まると,あとはLをどのように学習させたら良いかということを考える必要があります.そのLのための教師データは,以下の式で与えられます.

これだけだとなかなか説明が難しいので,画像を見て直感的な理解をした後に,教師データの意味を考えてみます.

画像7. を見ると,先ほどの式に出てきたvがあるので,おそらく画像中のvが教師データであることにまちがいないのですが,どのように設定しているかというと,青点をxj1, 赤点をxj2として見るときに,「xj1とxj2を結んだ線分上にのっていて」かつ「xj1とxj2を結んだ線分からの距離がσ以下である」場合にのみ,線分に向かう単位ベクトルをvという教師データとして採用し,それ以外はゼロベクトルとするような教師データを作っているということになります.基本的にPAFが表すのはキーポイントどうしのつながりなので,その出力はベクトルになります.また,実際に学習させるときには,全ての人に関するFieldを合体させて,キーポイントごとのFieldを作成し,それを教師データとして使います.それについては以下のAverage演算を使います.

Part Confidence Mapsを作成するモデル
Confidence Mapは画像5.のベージュ色の部分のStageにあたります.Confidence Mapを出力する各Stageの処理を記述すると,以下のようになります.

式の意味としては,最初のStageでは特徴量とPAFの出力結果を入力情報としConfidence Mapを出力します.それ以降のStageではそれら二つに加えて直前のConfidence Mapを入力に使用しています.式中のΦが表すのは3.2同様,畳み込み層を利用したニューラルネットのパラメータなので,処理は3.2とほとんど変わっていません.
次に,教師データをいかに作成するかについてですが,これはかなり単純で,そもそもMPⅡ Human Pose Dataset や COCOにはキーポイントの座標となる情報が記載されているデータセットが存在するので ,改めて作る必要はありません.しかし,そのままの教師データを使ってしまうと,ニューラルネットがキーポイントとなる座標をピンポイントで完璧に当てないといけないという,タスクとしては高い難易度になってしまうので,教師データとなる座標を中心にガウス分布のようななだらかなカーブを作るようにします.その処理が以下の式になります.

これを見るとわかるのは,座標を中心(最大値)にしながら,それ以外の座標ではなだらかに値が減少するカーブが描かれるということです.画像で見てみるとたしかに教師データが円を描くような形で,中心となる座標の付近をニューラルネットが出力したときにも,うまく学習ができるようになっています.

また,3.2同様,人ごとのMapから,キーポイントごとのMapに形式を合わせるために,Max演算を使います.

二つの情報のつなぎ合わせ
ここまで2つの過程の処理の仕方,学習するために必要なデータをどのようにしているかについて書きましたが,ここでは2つの過程を合わせてマッチングさせる方法について記述します.しかしながら,このマッチングに関してはそこまで複雑な数式はなく,以下の式による計算でマッチングの確からしさを表現します.

この式が表す意味については,式中の青部分があるキーポイントと別のキーポイントで結ばれる線分上の点pを表していて,ベージュ色の部分がキーポイントとキーポイントの間で計算される方向性です.これを線積分することで確からしさを算出しています.そして,各キーポイントの繋ぎ合わせ方zについて,Eを最大化するようなつなぎ方を選びます.


ここまでの計算によって,もっとも確からしい繋ぎ合わせが出力され,OpenPoseのアウトプットが完成します.
結果
論文内において記述されている実験結果について抜粋して紹介します.そもそもOpenPoseのねらいとしては,ボトムアップ型のモデルにおける精度と処理速度の向上であったため,その2点が達成されたかについて確認していきます.

まず表1では,OpenPoseで使用される手法が他手法と同等またはそれよりも遥かに早いことが示されています.また,各タスクの精度においても,それまでのSOTAとも比べて大きく変わらない,あるいはタスクによっては最高精度を出しているものもあります.

表2.では,[6]に比べて今回の手法が高精度になっていることを確認できます.ここでOpenPoseで失敗してしまっているケースを画像で確認してみます.

画像9.を見ていくと,人らしく映るものや,人と人の重なり方によっては検出が難しいことが伺えます.ただ,我々が普段観測している3Dな視覚情報に比べると,2Dの情報からその重なりを認識したりすることは困難であることは間違いないので,工夫が必要とは言われつつも,非常に良い結果が算出されているとも考えられます.一方,人らしきものを検出してしまうケースについては,街中にこの技術を実用しようとすると,わざと騙しやすいケースを作りかねなかったりするので,社会実装に向けてはこちらこそ工夫が必要になるのではないかと考えられます.
まとめ
今回はOpenPoseについて解説しました.また,Human Pose Estimationのタスク解決に向けたアプローチをいくつか紹介し,トップダウン型とボトムアップ型のアプローチに大きく分けて,それらの課題を踏まえることで,OpenPoseの立ち位置を浮かび上がらせ,各手法の考え方がクレイジーなアイデアでないことが理解いただけたかと思います.今後は,もう少し他の姿勢推定のアイデアを理解することで,この分野の理解をもう少し深めていきたいと思います.次回は,表1. にも出てきていたArtTrack[7]について解説をする予定です.
参考文献
[2] K. He, G. Gkioxari, P. Dolla ́r, and R. Girshick, “Mask r-cnn,” in ICCV, 2017.[3] U.IqbalandJ.Gall,“Multi-person pose estimation with local joint-to-person associations,” in ECCV Workshop, 2016.
[4] S.-E. Wei, V. Ramakrishna, T. Kanade, and Y. Sheikh, “Convolu- tional pose machines,” in CVPR, 2016.
[5] E. Insafutdinov, L. Pishchulin, B. Andres, M. Andriluka, and B. Schiele, “Deepercut: A deeper, stronger, and faster multi-person pose estimation model,” in ECCV, 2016.
[6] Z. Cao, T. Simon, S.-E. Wei, and Y. Sheikh, “Realtime multi-person 2d pose estimation using part affinity fields,” in CVPR, 2017.
[7] E. Insafutdinov, M. Andriluka, L. Pishchulin, S. Tang, E. Levinkov, B. Andres, and B. Schiele, “Arttrack: Articulated multi-person tracking in the wild,” in CVPR, 2017.
[8] K. Simonyan and A. Zisserman, “Very deep convolutional net- works for large-scale image recognition,” in ICLR, 2015.
関連記事

ABEJA Platformを利用してモデル学習(Abeja Platform試用報告 第2弾)
本記事では、機械学習向けPaaSの一つである「ABEJA Platform」を使って、 データセットの作成から学習、そして、学習済みモデルのWebサービス化までを 通してみました。 本記事はABEJA Platformの試用レポートです。
DeeperCut: A Deeper, Stronger, and Faster Multi-Person Pose Estimation Model 〜ArtTrackに向けて vol.2〜
本記事は,ArtTrackの解説に向けて,先行研究を順に解説していく記事の第2弾となります.前回の記事を踏まえての内容も多いので,この記事から読んでみようと考えている方にも読めるように,前回の記事のおさらいを前半で述べますが,DeepCutのより細かな解説については前回の記事から見ていただければと思います.
DeepCut: Joint Subset Partition and Labeling for Multi Person Pose Estimation 〜ArtTrackに向けて〜
Glia Comuputing 研究員の芦原です. 前回の記事では,姿勢推定問題を扱うOpenPoseについて解説をしました.今回からArtTrackの解説を行っていきたいと思っていましたが,ArtTrack単体を紹介し […]
この投稿へのトラックバック
トラックバックはありません。
- トラックバック URL
この投稿へのコメント