DeepCut: Joint Subset Partition and Labeling for Multi Person Pose Estimation 〜ArtTrackに向けて〜
Glia Comuputing 研究員の芦原です.
前回の記事では,姿勢推定問題を扱うOpenPoseについて解説をしました.今回からArtTrackの解説を行っていきたいと思っていましたが,ArtTrack単体を紹介しようとすると、積み重なった技術の結集を紹介することになるため,単独記事では超長編になってしまうという懸念がありました.したがって,ArtTrackの著者であるInsafutdinov さんのチームが2016年に出したDeepcutやDeepercutを紹介することで,ボトムアップ型の推定問題のアプローチとその課題,そしてその課題の解決に向けた改良についてうまく話を繋げられると思いました.したがって,ArtTrack編は3記事の構成になると思います.
なお,今回の記事については,後半部分の4章では定式化に関する内容を多く含んでおり,理解するにあたって統計の基本的な知識が必要だと思います.概要だけ知りたい方は,2章まで読んでください.
目次
紹介する論文の概要
今回紹介する論文はDeepcutと呼ばれる手法の元論文で,CVPR2016で発表されました.前回の記事と同様で,Human Pose Estimationと呼ばれる人の姿勢の推定問題を扱っています.この論文がこの分野に貢献した部分としては
・ボトムアップ型のアプローチを活用し,従来のトップダウン型のアプローチで課題だった部分を解決する糸口を示したこと
・ボトムアップ型のアプローチに起こるマッチングの問題を工夫し,整数計画問題に落とし込んだこと
という二つが上げられると思います.今回の記事では上記の2点について,もう少し詳しく述べていきたいと思います.各章の内容としては,2章でモデルの全体像の説明,3章でキーポイント導出の方法について解説,4章でマッチング方法に向けての問題の定式化とマッチングに使用した手法の解説,5章で実験の結果,6章でまとめと次回の予告になります.
モデルの全体像
この章ではモデルの全体像を紹介し,Deepcutのアプローチを大雑把に理解できるように解説したいと思います.前提として,ボトムアップ型のアプローチを大雑把に述べれば,姿勢の推定の鍵となるキーポイント(膝,顔,肘などの身体の部位の中心点など)を抽出して,その後にキーポイントを人物ごとにマッチングさせるという考え方です.言い換えれば,「候補点となるキーポイントの抽出→キーポイントどうしのマッチング」といった過程を経るものと考えます.このボトムアップ型のアプローチの紹介や,トップダウン型のアプローチとの違いについては,前回の記事の2章を読んでみてください.
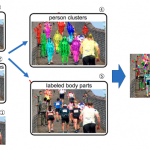
Deepcutの全体図を見ていきますと,以下のような図になります.

画像1. で行われている①〜⑤までの処理の概要を述べますと,
①カラー画像を入力として扱います
②CNN型のモデルを用いて,肘や顔といった人物を構成する部位(キーポイント)を抽出します
③ ②で抽出されたキーポイント同士の全てのつながりの組み合わせを描写しています
④ ③で得た組み合わせに関して,人物ごとにキーポイントをマッチングさせる手法を用いて,全ての組み合わせから人物ごとの組み合わせのみが残るようにします
⑤ 最後に,キーポイントの部位ごとの代表部分だけを残して,結果を出力します
という流れになります.①から⑤までの処理を見ていきますと,まさにボトムアップ型の「候補点となるキーポイントの抽出→キーポイントどうしのマッチング」というアプローチが実践されていると言えます.特にDeeputでは,③→④の処理についての貢献度が非常に高いと個人的に考えていますが,そもそもキーポイントをうまく抽出する①→②の処理もうまく行われていなければ,マッチングの技術だけではどうしようもありません.モデルが全体として何を行っているかを頭に入れたところで,次章では①→②の処理について注目し,もう少しその技術について見ていきます.
CNNを使ったキーポイントの抽出
この章では,画像1. の①→②の処理部分について,論文中で使われている方法について述べていきます.
Deepcutでは,主に二つのアプローチを使ってキーポイントを抽出しています.
A. Adapted Fast R-CNN(AFR-CNN)を使った抽出方法
B. Dense-CNNを使った抽出方法
論文中では,上記のAとBを別々に実装し,両方の結果が記載されています.個人的にはAFR-CNNのようなFast R-CNN型の方法論と,Dense-CNNのようなFully Connected CNNの方法論のどちらでもキーポイントの抽出に使えるという示唆は非常に後の論文に影響している気がします.論文中に二通りの分岐した手法を提示している論文は珍しいかと思います.ここからは,それぞれの手法の特長を述べていきます.
AFR-CNNを用いたキーポイントの抽出
AFR-CNNのアプローチの源泉はGirshickのFR-CNN[2]です.[2]では分類対象の物体を長方形(バウンディングボックスと呼ばれる)で囲い,さらにその物体が何であるかを分類する問題を解きます.AFR-CNNはこの方法論に影響を受けています.実際,FR-CNNで行われている処理は,以下のようなものになります.

※画像はhttps://www.cv-foundation.org/openaccess/content_iccv_2015/papers/Girshick_Fast_R-CNN_ICCV_2015_paper.pdf より使用
CNNがRegionを扱うようになったというところで大きなインパクトを与え,日本でも多くの方がこの図を目にしたことだと思います.この手法をもう少し抽象化して考えれば,画像中にある物体の位置とその分類が同時に行える方法ということです.AFR-CNNでは,認識したい物体をが人や車という大きな対象ではなく,肘や膝,頭といった人を構成する細かな部分になります.Deepcutが出る前に,そうした細かく区切った部位の認識を行うモデルはYangらの[3]やPishchulinらの[4]によって既に扱われていました.これらはあくまで画像中の人物が一人の時に対応できた手法ですが,Deformable Part Model[5]と呼ばれる手法を応用した技術で,後に考案される手法にも影響を与えています.

※画像はhttps://www.is.mpg.de/uploads_file/attachment/attachment/148/pishchulin13iccv.pdfより使用
AFR-CNNに話を戻すと,上記の[2],[4]に大きく影響を受けたモデルの考え方となっていて,[4]で扱われていたDeformable Part Model[5]を使うという工夫について踏襲しつつ,キーポイントを検出するモデルとして[2]の考え方を採用し,うまく学習するように各パラメータを変更した,といったところです.要は複合技ですが,[4]をうまくMulti Personに拡張し,[2]をより細かい部位について扱えるようにした,とも言うことができます.
Dense-CNNを使ったキーポイントの抽出
こちらはVGG[6]を少し改良した方式となっています.VGG[6]が考案された際の当時のタスクは,1枚の画像中に何が映っているか,という分類問題を解くものでした.したがって,VGGをそのまま扱うだけでは,画像を入力した際に,犬,とか猫,のような分類はできても,それがどこにあるかを示すことができません.そこで,Chenらの[7]を使った形式を採用し,出力をMapにするようにします.

Random Field(CRF)を用いて物体の領域を検出する.
※画像はhttps://arxiv.org/pdf/1606.00915.pdfより使用
[7]を使った方法を用いることで,VGGを使ったモデルでも,物体の位置を捕捉するモデルを考えることができます.そして,今回のDense-CNNでは,キーポイントのパーツごとに確率に関係するScoremapを出力することで,部位の位置とその部位の分類問題を同時に解くようにしています.後にDeeprcut[1]では大きな改良が加えられるので,今回に関しては手法の考え方のみ紹介し,これ以上の細かな工夫については省略します.
マッチング問題の定式化とDeepcutモデル
ここでは,前章のモデルのどちらかを使って抽出されたキーポイントどうしを,どのようにマッチングさせるかについて,その問題の定式化と,マッチングを実現するDeepcutモデルについて述べていきます.モデルの全体図から見た時には,この部分は画像1. の③→④に該当します.
マッチング問題の定式化
Deepcutでは,キーポイントとキーポイントのマッチング問題について,0-1整数計画問題に落とし込むという方法を用います.ここではそれについて述べます.
まず,定式化にあたり,0か1しか値を取らない,2つの変数と1つの媒介変数を考えます.それはそれぞれ,\(x_{dc}\),\(y_{dd’}\),\(z_{dd’cc’}\)というものです.添え字の\(d\)や\(d’\)は抽出されたキーポイントを指していて,抽出されたキーポイント全体の集合を\(D\)とします.添え字の\(c\)は顔や肘,膝といった体の部位を表すクラスを指します.クラス全体の集合を\(C\)とします.\(x_{dc}\)は,\(d\)がクラス\(c\)に属している時,1となり,それ以外では0を取ります.例えば,あるキーポイント\(d\)が肘と判定された時,\(c\)が顔だった時は,\(x_{dc}=0\)となり,\(c\)も肘だった時は,\(x_{dc}=1\)となります.\(y_{dd’}\)は,抽出された二つのキーポイントである\(d\)と\(d’\)が同じ人間のキーポイントだった場合に1となり,それ以外では0を取ります.\(z_{dd’cc’}\)は,\(z_{dd’cc’}= x_{dc} x_{d’c’} y_{dd’}\)というxとyに関する媒介変数で,\(z_{dd’cc’}=1\)であるということは,キーポイント\(d\)がクラス\(c\)と一致していて,かつキーポイント\(d’\)がクラス\(c’\)と一致して,かつ\(d\)と\(d’\)が同一人物であるということになります.
さて,これら3つの変数を与えることで,以下のような不等式を考えることができます.ビジュアルと共に見ることで,式の意味がわかりやすくなります.

※画像はhttps://pose.mpi-inf.mpg.de/contents/pishchulin16cvprPoster.pdfより使用
画像6.の上から解説していくと,一番上の式は,全ての体の部位は,1つのラベル付けにのみ対応するということで,簡単に言ってしまえば,キーポイント\(d\)は肘でもあり膝でもある!ということはありえないということを言っているだけです.真ん中の二つの式の意味は,\(d\)と\(d’\)が同一人物のものである場合,\(d\)も\(d’\)も,必ずどこかのクラスに属しているということを保証します.実装する際に,前章のAFR-CNNから100個のキーポイントが出力される際,たまにどのどのクラスに対しても確率の低いキーポイントを出力したりしますが,この二つの式が成り立つことによって,そういったキーポイントを排除することができます.最後の式は,各キーポイントの\(d\)と\(d’\)及び\(d’\)と\(d”\)が同じ人物のキーポイントであるとわかった時,\(d\)と\(d”\)が同じ人物のキーポイントであることを示しています.
ここまでの定式化の後に,前章で述べたモデルから出てくる出力について考えてみると,AFR-CNNもDense-CNNも,キーポイントの候補となる\(d\)を出していますが,ただ\(d\)をを出しているだけでなく,その\(d\)があるクラス\(c\)に属しているかどうかの確率を出していることになります.その確率を\(p_{dc}\)として表記し,\(p_{dd’cc’}\)を,キーポイント\(d\)と\(d’\)が同じ人物で,\(d\)がクラス\(c\)に一致し,\(d’\)がクラス\(c’\)と一致している確率として考えると,マッチングも含めたDeepcut全体で目指す問題は,以下の問題の最適化として考えることができます.

α,βが初めて出てきていますが,以下の式で定義された変数です.

もう少しこれを噛み砕くと,以下のような考え方になります.

要は,キーポイントの抽出部分で\(< \alpha , x > \)を,マッチング部分で\(< \beta , z > \)を最適化するような問題としてシンプルに書くことができます.すでに\(< \alpha , x > \)の部分は,前章までの部分がやってくれるということなので,\(< \beta , z > \)の最適化をどのように解決していくかについて述べていきます.
Deepcutモデルによるマッチング最適化
前の節によって,マッチング問題の最適化がシンプルな式で書けたので,あとは\(< \beta , z > \)をどのように最適化していくかについて考えれば良いことになります.言い換えれば,\(p_{dd’cc’}\)をどのようにして求めるかということになりますが,ここでキーポイントの抽出の際に得られる他の情報を特徴量として活用することを考えます.例えばAFR-CNNでは,ただ単にキーポイント\(d\)と,そのキーポイント\(d\)がクラス\(c\)に属している確率\(p_{dc}\)を求めるだけでなく,FR-CNNをベースとしている以上,長方形の矩形や,その長方形の大きさやIoU[7],特徴量を出力しています.これらの特徴量を,マッチングのための特徴量として,ペアーワイズ特徴量\(f_{dd’}\)とします.ただやみくもにペアーワイズ特徴量を集めるだけではなく,\(z_{dd’cc’}\)を考えた時に,\(c=c’\)である場合と,\(c≠c’\)である場合に分けてそれぞれペアーワイズ特徴量になるものを集めていきます.
今回の論文の場合,\(c=c’\)の時に関しては,AFR-CNNなどから出力された長方形の距離に関係する指標や,IoUに関係する指標を\(f_{dd’}\)として集めていきます.\(c≠c’\)の場合に関しては,空間関係を表す,二つのキーポイントの距離と角度を集め,それぞれを\(S_{dd’}\)と\(R_{dd’}\)と置くことで,\(p(z_{dd’cc’} = 1 | S_{dd’}, R_{dd’}) \)を求めていきます.また,キーポイントの抽出時に得られる\(f_{p_{dc}} = (p_{d1}, … , p_{dc}) \),\(f_{p_{d’c}} = (p_{d’1}, … , p_{d’c}) \)も特徴量として集めます.これらの特徴量を元に,\(p_{\theta_{cc’}}) = N(0, \sigma^2) \)となるような事前分布を与えたロジスティックモデル

を考えることができます.最終的にパラメータの\(\theta_{cc’}\)をロジスティック回帰で求めてマッチング最適化問題を解くこととなります.
実際のところ,算出したキーポイントの候補点(今回の論文中では,キーポイントの抽出の時点で100点の候補点が出力される)の全ての組み合わせについてそのつながりの尤度を計算している形式となっているため,前回紹介したOpenPoseに比べて解くにはかなりの計算時間がかかってしまいますが,つながりの確からしさを特徴量から回帰で求めていくという考え方は,素直な考え方で精度も出やすいと考えられます.
上記の問題を簡単にビジュアル化したものが以下になります.

※画像はhttps://pose.mpi-inf.mpg.de/contents/pishchulin16cvprPoster.pdfより使用
実験結果
Deepcutを使った結果は,MPⅡ Human Pose Dataset を使ったSingle Personの形式では以下のような結果だったようです.トップダウン型の当時のSOTAとほぼ互角の状態です.

また,Multi-Personなデータに対しては,当時のSOTAでした.

実験の結果からわかるのは,当時のSingle PersonのタスクのSOTAとほぼ互角な結果を出しつつ,Multi PersonではSOTAというかなり優れた手法であったということでした.また,Failure caseから,人と人が複雑に重なったケースに関してはまだ課題というところを挙げているものの,非常に良い出力のようにも見えます.

まとめ
今回は,ArtTrackの理解に向けて,同じ著者グループのDeepcutについて書きました.ボトムアップ型の中でも原点のように扱われていることが多く,その中身も,ボトムアップ型の考え方のエッセンスとなるような,マッチング問題に向けた定式化や,キーポイントの抽出などがメインコンテンツとして考えられ,かなり読む価値の高い論文だったと思いました.次回はDeepcutをさらに改良した,Deepercutについて書きたいと思います.
参考文献
[1]E. Insafutdinov, L. Pishchulin, B. Andres, M. Andriluka, andB. Schiele. Deepercut: A deeper, stronger, and faster multiperson pose estimation model. In ECCV’16.
[2]R. Girshick. Fast r-cnn. In ICCV’15.
[3] Y. Yang and D. Ramanan. Articulated human detection with flexible mixtures of parts. PAMI’13.
[4]L.Pishchulin,M.Andriluka,P.Gehler,andB.Schiele.Strong appearance and expressive spatial models for human pose estimation. In ICCV’13.
[5]Pedro F. Felzenszwalb, Ross B. Girshick, David McAllester, and Deva Ramanan. “Object detection with discriminatively trained part-based models.” IEEE, 2010.
[6]K. Simonyan and A. Zisserman, “Very deep convolutional net- works for large-scale image recognition,” in ICLR, 2015.
[7]https://www.pyimagesearch.com/2016/11/07/intersection-over-union-iou-for-object-detection/
[8]M. Eichner and V. Ferrari. We are family: Joint pose estima- tion of multiple persons. In ECCV’10.
関連記事
Start:GliaComputing技術ブログ
株式会社GliaComputingは、ディープラーニング、機械学習、統計など各方面に豊富な経験を持ったエンジニアが集まって設立したスタートアップです。 https://www.glia-computing.com/ 技術 […]

ABEJA Platformを利用してモデル学習(Abeja Platform試用報告 第2弾)
本記事では、機械学習向けPaaSの一つである「ABEJA Platform」を使って、 データセットの作成から学習、そして、学習済みモデルのWebサービス化までを 通してみました。 本記事はABEJA Platformの試用レポートです。
DeeperCut: A Deeper, Stronger, and Faster Multi-Person Pose Estimation Model 〜ArtTrackに向けて vol.2〜
本記事は,ArtTrackの解説に向けて,先行研究を順に解説していく記事の第2弾となります.前回の記事を踏まえての内容も多いので,この記事から読んでみようと考えている方にも読めるように,前回の記事のおさらいを前半で述べますが,DeepCutのより細かな解説については前回の記事から見ていただければと思います.
この投稿へのトラックバック
トラックバックはありません。
- トラックバック URL
この投稿へのコメント